

Principal Component Analysis (PCA)
For this project, a database was selected which could contain a considerable number of instances, the data is prepared to carry out the PCA method. This method is used for the reduction of the dimensionality of the data with the purpose of using a specific percentage of information and obtaining better performance of the machine learning methods.

Datasets
The databases used were type of star and cancer. These sites can be seen in their own links.
Data preparation
The preparation of the data is the same as that carried out in the projects mentioned above.


Data analysis
Applying PCA
In this section, the PCA method will be applied to analyze and reduce the dimensionality that we want, which in this case is 90, 80, and 70 percent of the information of the data.
Training
Desition tree & KNN
The models that were trained to perform classification were the decision tree and k nearest neighbors. 80 percent of the data was split as the training set while the remaining 20 percent as the test set.


Results
In the following tables, It can be seen all the combinations that were made for the two databases. Variations in the normalization application, percentage of PCA information, and machine learning models were used.
Results for the star type database.
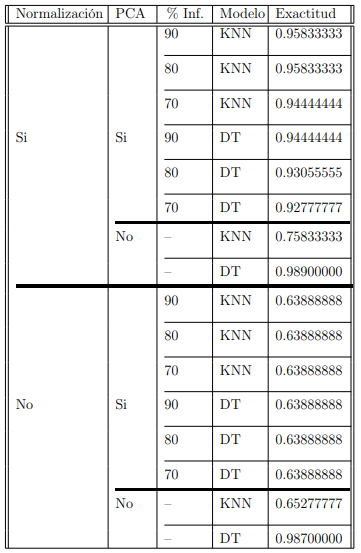
Results for the cancer database.
